Ensemble Learning for Multi-Regional Food Price Prediction in Indonesia

I collaborated on a project to tackle the challenge of volatile food commodity prices in Indonesia. Working alongside Adzka Bagus Juniarta and Rayhan Adi Wicaksono at Universitas Gadjah Mada, we aimed to create accurate predictions for 13 key staples across 34 provinces using data from the National Food Agency (Bapanas). This work not only highlights the power of ensemble methods in handling complex, multi-regional data but also contributes to food security and policy-making in a diverse economy like Indonesia's.
The Challenge: Volatility in Food Prices
Indonesia's archipelago geography leads to significant price disparities for essentials like rice, onions, and cooking oil due to factors such as climate variations, supply chain issues, and regional economic differences. Traditional statistical models often fall short in capturing these temporal and spatial dependencies, resulting in unreliable forecasts that can exacerbate food insecurity and market inefficiencies.
Our dataset spanned January 2022 to December 2024, encompassing daily prices for commodities like beras medium (medium rice), cabai merah keriting (curly red chili), and minyak goreng curah (bulk cooking oil). With over 34 provinces and multiple commodities, the data presented challenges like missing values (averaging 3-5% per commodity) and regional correlations.
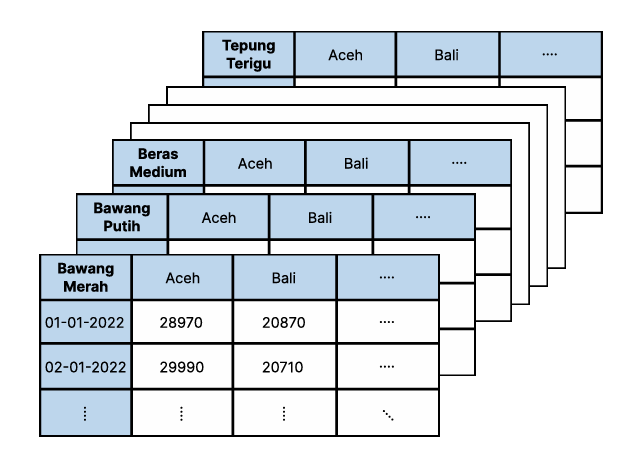
Methodology: From Preprocessing to Ensemble Modeling
We began with thorough data preprocessing to handle null values using forward and backward fill techniques, ensuring continuity in the time series. We excluded unstable data prior to July 14, 2022, due to large gaps identified in exploratory data analysis (EDA).
EDA revealed insights like high null percentages in certain commodities (e.g., 15.93% in bulk cooking oil) and strong Pearson correlations between neighboring provinces, such as those on Java Island.
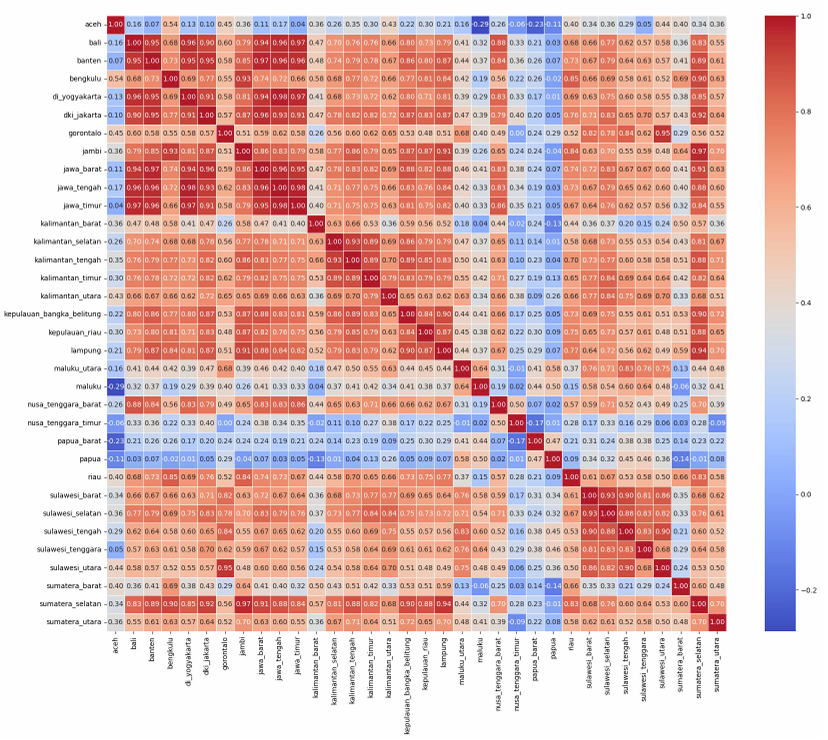
For feature engineering, we introduced national average prices as a covariate to capture broader trends. We experimented with a range of models, from simple baselines like Naive and Seasonal Naive to advanced deep learning approaches such as Chronos, Temporal Fusion Transformer (TFT), and PatchTST. Evaluation used Mean Absolute Percentage Error (MAPE) on a validation set matching the forecast horizon.
The standout was our Weighted Ensemble model, which combined predictions from top performers via greedy optimization. This ensemble outperformed individual models, especially after data cutoff.
Results: Achieving High Accuracy
On national averages, the Weighted Ensemble achieved a MAPE of 3.29% (cutoff scenario), surpassing AutoETS (4.50%) and TFT (4.81%).
For provincial forecasts, it reached 3.28% MAPE, better than baselines like Seasonal Naive (8.23%) and deep models like DeepAR (16.56%).
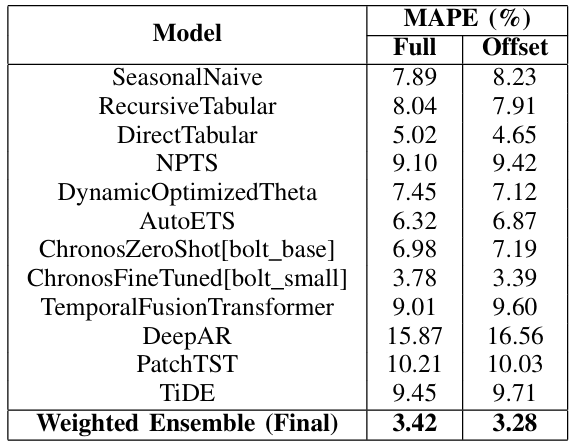
These results demonstrate the ensemble's robustness in multi-commodity, multi-regional settings.
Conclusion: Implications and Future Work
This project underscores the value of ensemble learning in enhancing food price predictions, aiding government interventions and economic planning. By integrating national trends and addressing regional gaps, we provided a reliable tool for volatility mitigation.
In the future, incorporating external variables like weather data or trade policies could further improve accuracy. This work strengthened my skills in Python-based time series libraries (e.g., Darts, GluonTS) and deep learning frameworks, and I'm excited to apply similar approaches to other real-world problems.
DS/ML/AI Engineering
Motion Matters: Human Fall Detection Classification for Safety Insight
Statistic & Data Analysis
Evaluating the Impact of Meteorological Data on PM2.5 Prediction Using Tree-Based Machine Learning Models
DS/ML/AI Engineering