Motion Matters: Human Fall Detection Classification for Safety Insight
In an era where technology intersects with human well-being, fall detection stands out as a critical application of artificial intelligence. Falls can have severe consequences, especially for the elderly and those with disabilities, often leading to injuries that require immediate attention. This project, part of the Data Slayer 2.0 machine learning competition, aimed to classify static images into fall and non-fall categories using advanced computer vision techniques. By building a robust model, the goal was to enable early detection and potentially save lives through automated systems like surveillance cameras or wearable devices.
The dataset consisted of images captured from multiple subjects performing various activities, divided into fall types (e.g., forward, backward, left, right, standing, sitting) and non-fall activities (e.g., laying, squatting, stretching, jumping, picking, walking). The training data was organized by subjects, with a focus on ensuring the model generalizes well to unseen individuals, mimicking real-world scenarios.

Data Exploration and Preparation
The first step involved understanding the data structure. The dataset was hierarchical, with folders for subjects and sub-categories of falls and non-falls. Exploratory data analysis revealed redundancies—many consecutive frames showed nearly identical poses, which could lead to overfitting if not addressed.
To mitigate this, undersampling was applied by selecting every nth frame (e.g., where frame number mod n = 0). This reduced the dataset size while preserving essential variations, allowing the model to generalize better with less training memory.
Additionally, outliers were removed, such as images of a subject walking diagonally, which differed from the horizontal movements in other samples. The data was then split: subjects 2, 3, and 4 for training, and subject 1 for validation, simulating the test set's unseen subjects.
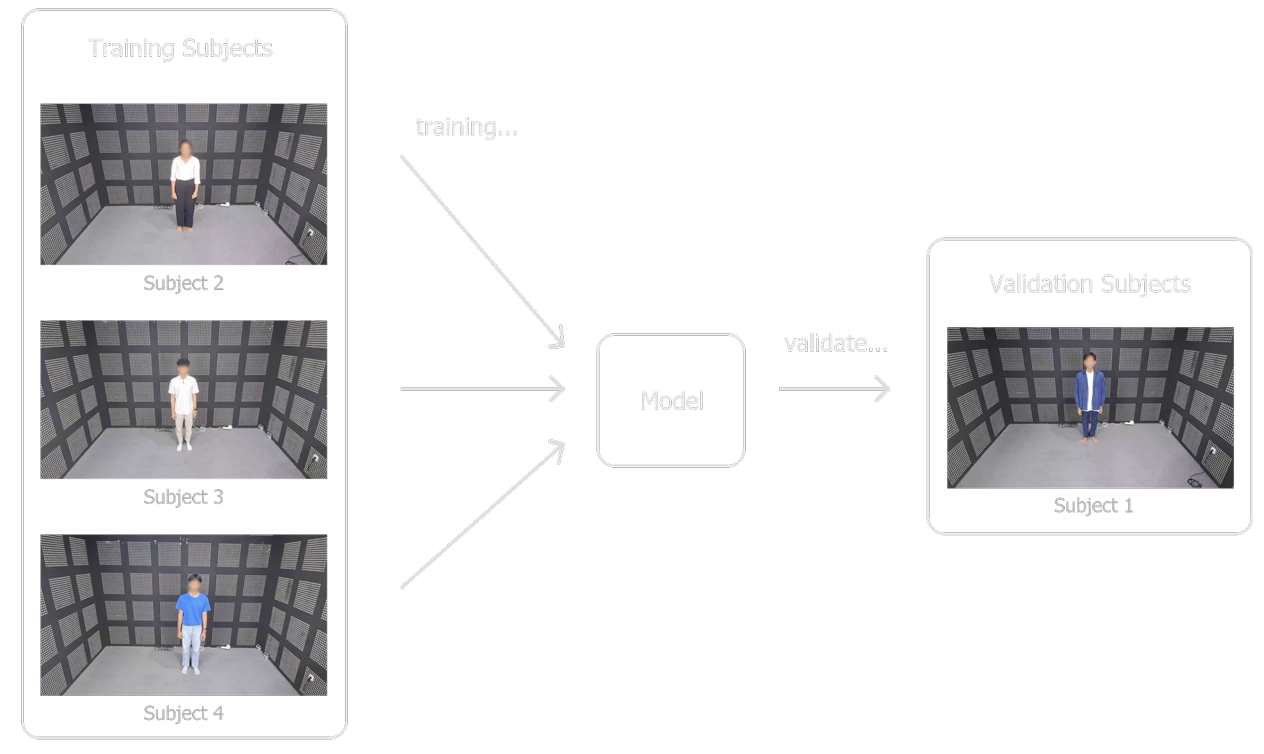
Preprocessing and Augmentation
Images were preprocessed by resizing to a uniform dimension and converting to grayscale, as color information was deemed unnecessary—focusing the model on shapes and poses instead. This also optimized resource usage during training.
To enhance dataset diversity, simple augmentations like small-angle rotations were applied. Furthermore, Mixup augmentation was employed, blending images and labels with a beta distribution parameter alpha=0.4. This encouraged the model to learn smoother decision boundaries and act as regularization, improving generalization.
Model Architecture and Training
The core of the project was a multitask EfficientNetB7 model, pretrained on ImageNet and fine-tuned for this task. It predicted both binary fall/non-fall and multiclass activity types simultaneously, with a custom head: one output for binary classification using Binary Cross-Entropy loss, and 12 outputs for type classification using Cross-Entropy loss.
Training used Adam optimizer with an initial learning rate of 5e-5, reduced on plateau if validation loss stalled. Early stopping prevented overfitting, and metrics like accuracy and F1-score were monitored for both tasks.
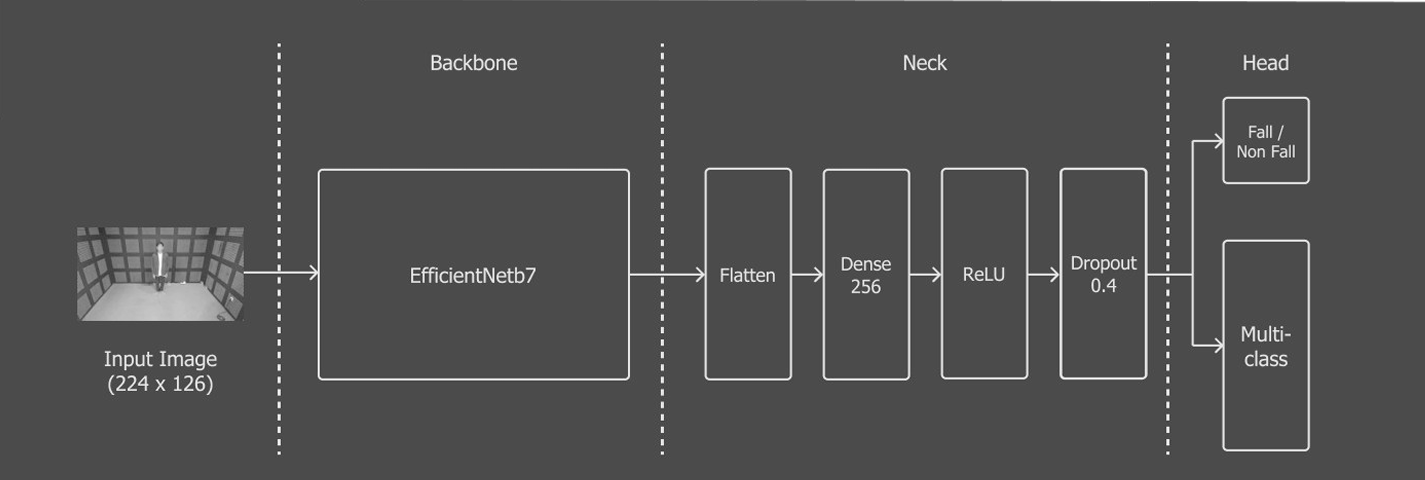
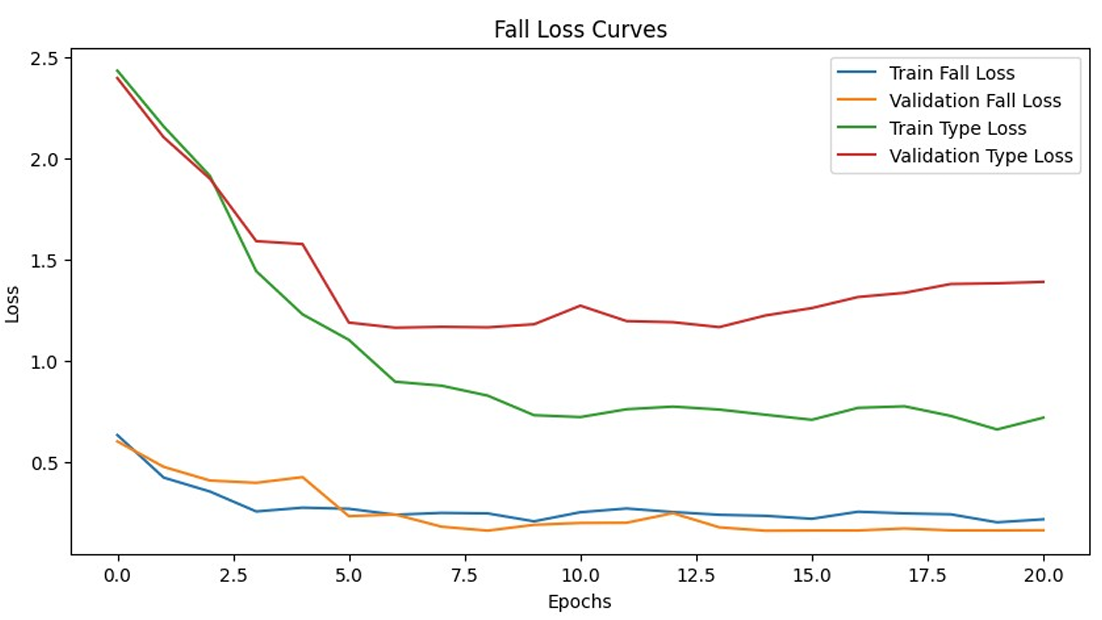
The training process ran for up to 30 epochs, with Mixup applied on-the-fly. Loss curves showed steady convergence, with training loss decreasing while validation loss stabilized, indicating good generalization.
Results and Evaluation
The best validation performance achieved a fall accuracy of approximately 98.6% and an F1-score of around 95.5%, with type accuracy at 64.7%. Misclassified images were visualized to identify patterns, such as confusion between similar poses like left and right falls.
A multiclass confusion matrix highlighted challenges in distinguishing visually similar activities, like squatting misclassified as standing or stretching. However, the binary fall detection remained robust, correctly categorizing most instances despite type errors.
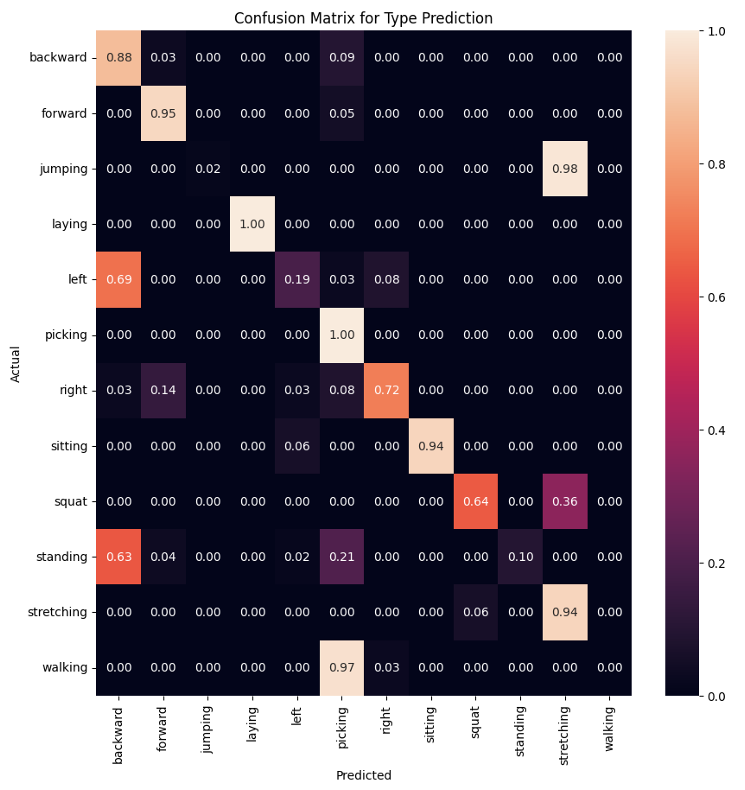
On the held-out validation set (simulating the test set), fall accuracy reached 96.8%, confirming the model's effectiveness.
Conclusion
This project demonstrates the power of computer vision in safety applications. By leveraging EfficientNet with multitask learning, undersampling, and augmentation, a reliable fall detection system was developed. Future improvements could include incorporating temporal information from video sequences or ensemble methods for higher type accuracy.
The model was saved and used for test set predictions, achieving competitive results in the Data Slayer competition. This work not only showcases skills in data analysis and machine learning but also contributes to real-world impact in health and safety.

Statistic & Data Analysis
Ensemble Learning for Multi-Regional Food Price Prediction in Indonesia
Statistic & Data Analysis
Evaluating the Impact of Meteorological Data on PM2.5 Prediction Using Tree-Based Machine Learning Models
Statistic & Data Analysis