Evaluating the Impact of Meteorological Data on PM2.5 Prediction Using Tree-Based Machine Learning Models
Air pollution, particularly fine particulate matter (PM2.5), poses a significant threat to public health and the environment, especially in tropical regions like Yogyakarta, Indonesia. These tiny particles, smaller than 2.5 micrometers, can penetrate deep into the lungs and bloodstream, contributing to respiratory and cardiovascular diseases. While emissions from human activities are major contributors, meteorological factors such as temperature, humidity, and wind play a crucial role in the dispersion and concentration of PM2.5. In this project, conducted as part of my internship at the Yogyakarta Climatology Station (BMKG), I explored whether weather data alone could effectively predict PM2.5 levels using tree-based machine learning regression models.
The goal was twofold: to evaluate the accuracy of these models when relying solely on meteorological inputs and to identify which weather variables had the most influence on PM2.5 concentrations. By isolating meteorological data, this study provides unique insights into the exclusive contributions of weather patterns, which can inform air quality management strategies in similar tropical climates.
Methodology
Data was sourced from the Yogyakarta Climatology Station, covering hourly records from July to December 2023. The dataset included 11 meteorological features:
- Average air temperature (°C)
- Maximum air temperature (°C)
- Minimum air temperature (°C)
- Average relative humidity (%)
- Rainfall (mm)
- Average wind speed (m/s)
- Maximum wind speed (m/s)
- Average wind direction (degrees)
- Average solar radiation (W/m²)
- Maximum solar radiation (W/m²)
- Air pressure (hPa)
Preprocessing involved outlier removal using the Interquartile Range (IQR) method and handling missing values by dropping rows where PM2.5 was absent. The dataset was split into 80% training and 20% testing sets.
Five tree-based regression algorithms were tested with default hyperparameters for fair comparison:
- Gradient Boosting Regressor (GBR)
- Random Forest Regressor (RFR)
- LightGBM Regressor (LGBM)
- Extra Trees Regressor (ETR)
- XGBoost Regressor (XGBR)
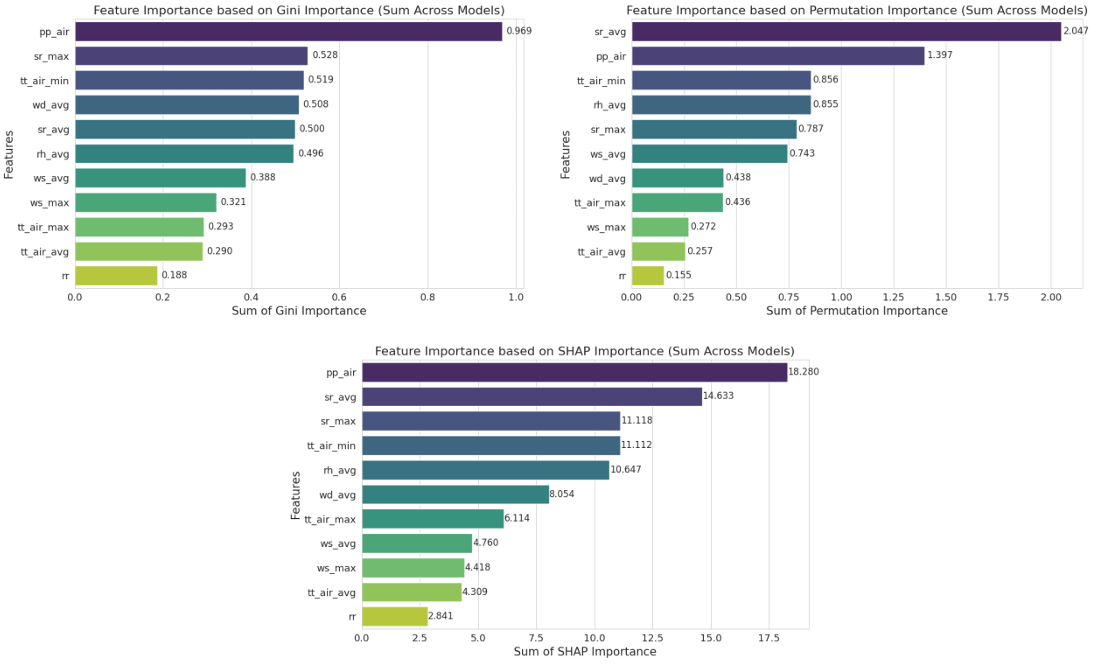
Models were evaluated using Root Mean Squared Error (RMSE) and R-squared (R²) metrics. Feature importance was analyzed via three methods: Gini Importance, Permutation Importance, and SHAP (SHapley Additive exPlanations) to ensure robust insights and mitigate biases.
Results and Analysis
The models demonstrated moderate predictive power, with LightGBM emerging as the top performer. Here's a summary of the performance metrics:
| Model | RMSE | R² |
|---|---|---|
| LightGBM Regressor | 10.9800 | 0.3118 |
| Random Forest Regressor | 11.0141 | 0.3075 |
| Extra Trees Regressor | 11.0141 | 0.3075 |
| Gradient Boosting Regressor | 11.2797 | 0.2737 |
| XGBoost Regressor | 11.6605 | 0.2239 |
LightGBM's superior results align with its efficiency in handling non-linear relationships and large datasets, as noted in prior studies. While the R² values indicate room for improvement (suggesting about 31% of PM2.5 variance explained by weather alone), this underscores the limitations of excluding emission sources but highlights weather's independent role.
Feature importance analysis revealed consistent patterns across methods:
- Air pressure (pp_air): Ranked highest overall, influencing PM2.5 through atmospheric stability.
- Solar radiation (average and maximum): Key driver, especially in dry seasons where high radiation accelerates pollutant formation.
- Minimum air temperature and average relative humidity: Significant contributors, affecting particle dispersion.
- Rainfall: Least influential, possibly due to infrequent heavy rains in the study period.
These findings emphasize how tropical weather dynamics, like high solar intensity during dry months, exacerbate pollution.
Conclusion and Key Learnings
This project demonstrates that meteorological data can provide valuable, albeit partial, predictions for PM2.5 levels using tree-based ML models. LightGBM's effectiveness makes it a promising tool for real-time forecasting in resource-constrained settings. The insights into key variables like air pressure and solar radiation can guide targeted interventions, such as public alerts during high-risk weather conditions.
Through this work, I gained hands-on experience in data preprocessing, ensemble modeling, and interpretability techniques like SHAP. Future enhancements could include hyperparameter tuning, incorporating emission data, or exploring time-series models like LSTM for better temporal accuracy. This study not only advances environmental data science but also contributes to sustainable urban planning in regions like Yogyakarta.
Statistic & Data Analysis
Predicting Judicial Sentences: Analyzing Indonesian Court Verdicts with NLP and ML
DS/ML/AI Engineering
Motion Matters: Human Fall Detection Classification for Safety Insight
DS/ML/AI Engineering