Citation Link Prediction: Building a Multi-Feature Similarity-Based Recommendation System
Predicting whether one scientific paper will cite another is a key task in bibliometrics and information systems. In this competition, the goal was to classify pairs of papers as referenced (1) or not (0) based on metadata (titles, authors, dates, etc.) and full-text content. The dataset was highly imbalanced, with only 1.05% positive cases, making it tricky to achieve reliable predictions. The evaluation metric was the Matthews Correlation Coefficient (MCC), which is ideal for imbalanced binary classification.
My approach focused on extracting rich signals from both metadata and text to capture bibliographic and semantic relationships, ultimately building a robust recommendation system for references.
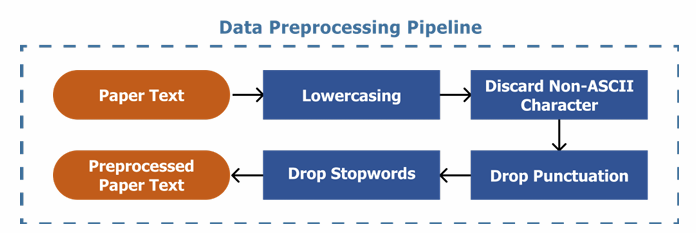
Data Exploration and Pre-processing
Initial exploratory data analysis (EDA) revealed the sever# class imbalance and the need for careful handling of long text documents. I analyzed the distribution of word counts in papers, finding that the average segment before the "Introduction" was around 415 words. To optimize for transformer models (which have input limits), I selected the first 400 words as a proxy for abstracts while also experimenting with chunking the full text.
Text pre-processing included lowercasing, removing non-ASCII characters, punctuation, and stopwords to prepare clean inputs for feature extraction.
Feature Engineering
I engineered 67 features divided into metadata-based and text-derived categories:
- Metadata Features: Included publication intervals (days, months, years differences), overlap metrics (matched words count, Jaccard similarity for authors and concepts), and author citation statistics (aggregates like mean, max, sum of total citations per paper, plus differences between pairs).
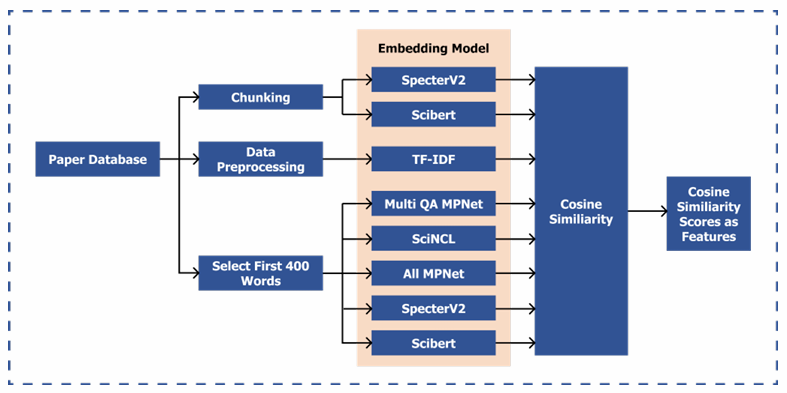
- Text-Derived Features: Leveraged transformer embeddings from models like SPECTER2, SciBERT, SciNCL, Multi-QA-MPNet, and All-MPNet. Cosine similarity was calculated on embeddings. Additional features included regex-based author mentions, BM25 retrieval scores, and TF-IDF title similarity.
For long texts, I combined first-400-words embeddings with chunked full-text embeddings (aggregated via mean pooling), as this complementary approach boosted performance.
Modeling
I started with Logistic Regression as a baseline, then explored Gradient Boosted Tree models: LightGBM, XGBoost, and CatBoost. Using 5-fold cross-validation, I tuned thresholds based on MCC to handle imbalance. The final model was an ensemble of the three GBT models via soft voting, which improved robustness and metrics.
Results
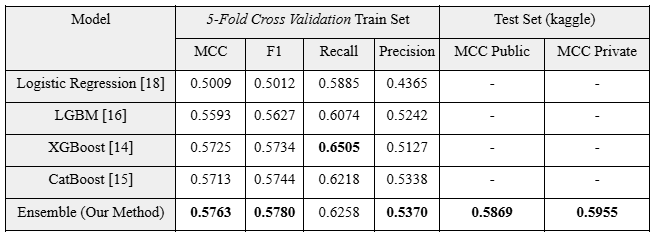
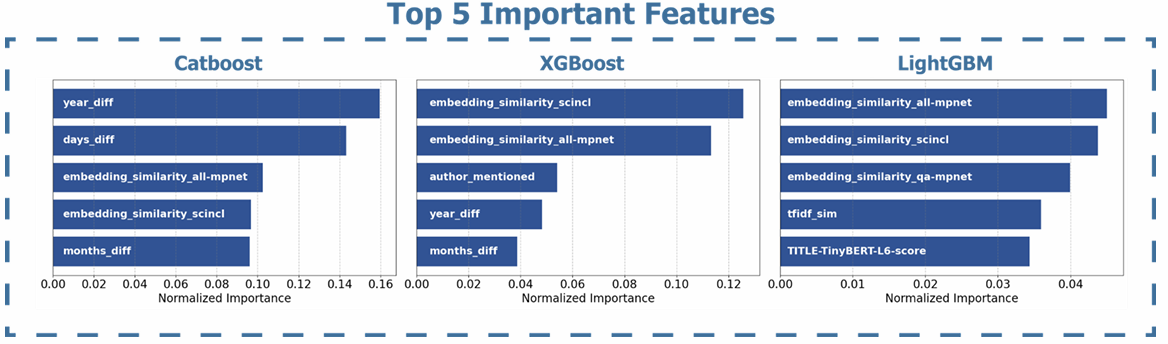
The ensemble model outperformed individual models, achieving a cross-validation MCC of 0.5769 and strong Kaggle scores (Public: 0.5869, Private: 0.5955). Feature importance analysis showed diverse signals: embedding similarities (e.g., SciBERT, SPECTER2) were top contributors, highlighting the value of semantic representations.
Adding varied embeddings progressively increased MCC, and combining pre-processing methods (first 400 words + chunking) yielded the best results. This demonstrated how multi-faceted features capture complex citation patterns.
Conclusion
This project showcased my skills in NLP, feature engineering, and ensemble modeling to solve a real-world citation prediction problem. By integrating metadata and advanced text representations, the system not only predicted links accurately but also provided insights for reference recommendations. Future work could explore newer domain-specific transformers for even better embeddings.
This experience reinforced the importance of handling imbalanced data and long texts in scientific domains, skills I've applied in subsequent projects.