Driver Drowsiness Classification
In the fast-paced world of autonomous and assisted driving technologies, ensuring driver alertness is paramount to preventing accidents. As part of the Data Slayer 3.0 machine learning competition, my team—"manud adz wae" consisting of Adzka Bagus Juniarta, Adji Dharmawan Indrianto, and Anggito Muhammad Amien—tackled the challenge of classifying driver drowsiness from video footage. Our solution leveraged cutting-edge techniques like precision temporal chunking, action-level reframing, and low-rank adaptation (LoRA) on the VideoMAE v2-Huge model, delivering robust performance that generalized well to unseen subjects. This project not only secured strong leaderboard results but also demonstrated practical real-time applicability for in-vehicle safety systems.
The Problem: Combating Drowsiness on the Roads
Driver drowsiness is a silent killer, contributing to countless road incidents worldwide. Traditional detection methods often rely on simplistic cues like eye blinks or head nods, but they falter in varied lighting, poses, or when subtle micro-expressions are involved. The competition dataset simulated real-world scenarios, capturing drivers from front and side camera angles performing actions indicative of drowsiness (e.g., microsleep or yawning) versus alertness (e.g., focusing or talking). The goal was binary classification—drowsy or non-drowsy—but with a twist: the data's temporal nature and subject variability demanded a model sensitive to fine-grained behaviors without overfitting to individual faces.

Examples of dataset actions: Front Microsleep, Front Yawning, Side Microsleep, Side Yawning (drowsy); Front Focus, Front Talking, Side Focus, Side Talking (non-drowsy). The dual-camera setup captures comprehensive facial pose variations.
Dataset and Preprocessing: Building a Solid Foundation
The dataset comprised videos from 15 unique subjects, each exhibiting a mix of drowsy and non-drowsy behaviors. To address challenges like train-test distribution shifts and class imbalances (e.g., fewer microsleep instances), we implemented precision temporal chunking: manually annotating and segmenting long videos into consistent 30-frame clips at 30 FPS, ensuring representative samples without bias.
We also focused on region-of-interest (ROI) preprocessing for the face, comparing strategies like anchored cropping, smooth tracking, self-segmentation masking, and our chosen method—recalculating the ROI every frame with 30% padding. This approach added natural jitter, acting as implicit augmentation and improving robustness to head movements.
To combat overfitting on a small dataset, we applied video augmentations using the Albumentations library: HorizontalFlip for pose symmetry, CoarseDropout to simulate occlusions (e.g., hands or reflections), and ColorJitter for lighting variations. These were consistently applied across frames in each clip, enhancing generalization without distorting temporal consistency.
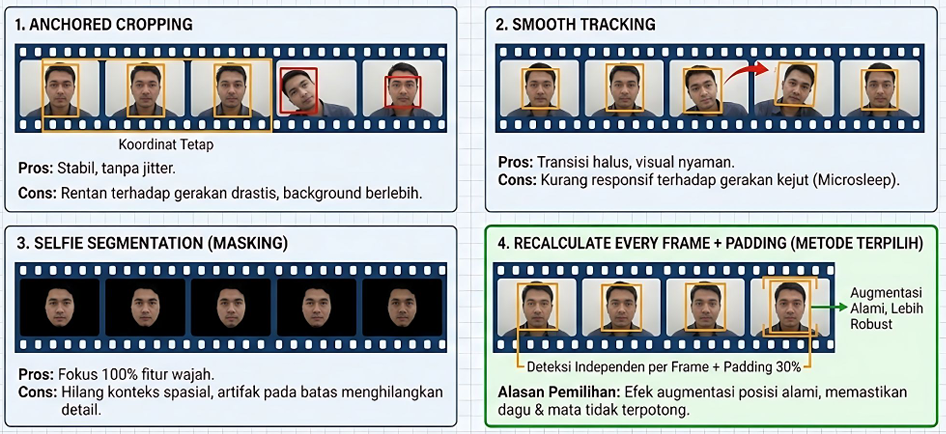
Comparative ROI preprocessing strategies: Our recalculate-every-frame method with padding ensures maximal robustness by handling dynamic head positions naturally.
Methodology: Innovative Model Architecture and Training
We conducted a comparative study of architectures, starting with baselines like R(2+1)D (factorized CNNs) and InternVideo (a multimodal foundation model). While these showed promise, they lacked sensitivity to micro-expressions. VideoMAE v1 improved efficiency through high masking (90%) in self-supervised pre-training, but VideoMAE v2 emerged as the state-of-the-art choice with dual masking and scaling, excelling at capturing subtle temporal contexts like partial eye closures.
To adapt the massive VideoMAE v2-Huge (600M+ parameters) to our task without excessive compute, we used LoRA—freezing the pre-trained backbone and fine-tuning low-rank adapters (rank=16) on feed-forward and attention layers. This reduced trainable parameters to under 2%, enabling efficient training on limited resources.
A key innovation was action-level reframing: Instead of direct binary classification, we first trained on four sub-actions (Yawning, Microsleep, Focus, Talking), then mapped them to drowsy/non-drowsy. This forced the model to learn explicit distinctions (e.g., mouth movement in yawning vs. talking), sharpening decision boundaries.
For validation, we employed subject-independent group 5-fold cross-validation, grouping data by subject IDs to prevent leakage and simulate real-world unseen drivers. This ensured the model recognized behaviors, not identities, with natural label stratification across folds.
Training optimizations included FP16 mixed precision for memory efficiency, focal loss (gamma=2.0) to prioritize hard samples like minorities (yawning/microsleep), weighted random sampling for balance, AdamW optimizer, and a 0.01 weight decay over 15 epochs.
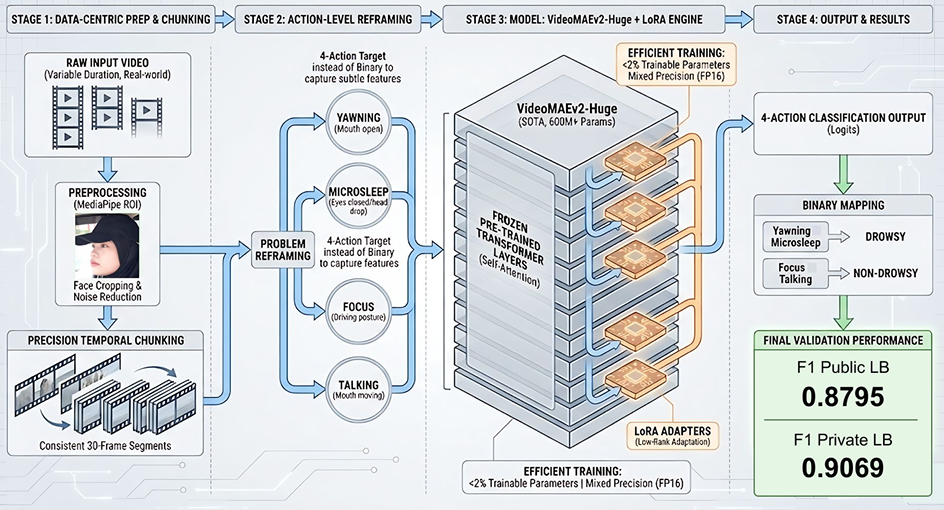
Project pipeline overview: From precision temporal chunking and action reframing to efficient LoRA fine-tuning on VideoMAE v2-Huge, achieving F1 scores of 0.8795 (public) and 0.9069 (private).
Experiments and Results: Ablation Insights and Performance
Ablation studies validated our choices. Direct binary training yielded an F1 of 0.8520, but action reframing boosted it to 0.8795, confirming its value in feature separation. Among ROI methods, recalculate-every-frame outperformed others (e.g., masking at 0.8250) by preserving spatial context. Model scaling showed linear gains, with Huge outperforming Large by ~1.1%.
Out-of-fold evaluation revealed strong per-action metrics: Macro F1 of 0.879 for four actions, mapping to 0.910 binary. On the leaderboard, we achieved 0.8795 (public) and 0.9069 (private), indicating excellent generalization.
Inference latency was analyzed for real-time feasibility: Preprocessing at 937.5 ms and model inference at 345.98 ms per 30-frame clip totaled 1.283 seconds—well within safe bounds for microsleep durations (1-30 seconds), allowing timely alerts.
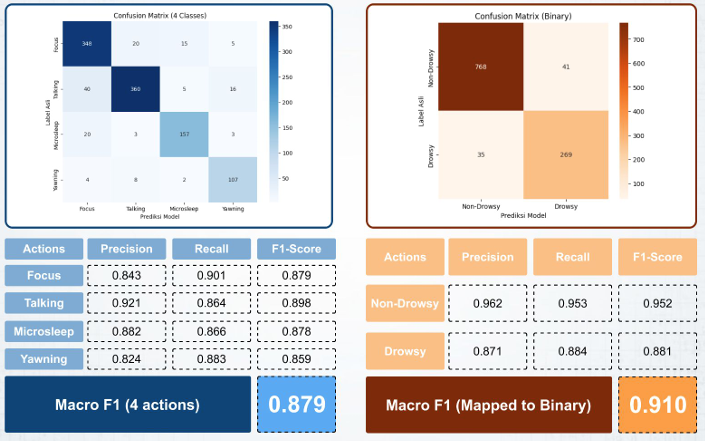
Training evaluation results: Confusion matrices and F1 scores demonstrate high precision across actions, with macro F1 of 0.879 (4-actions) and 0.910 (binary).
Conclusion: Lessons Learned and Future Impact
This project highlighted the power of combining advanced video foundation models with targeted adaptations like LoRA and reframing to solve real-world problems efficiently. By addressing data leakage, imbalances, and computational constraints, we built a system that's not just accurate but deployable in vehicles for enhanced safety.
Looking ahead, integrating multimodal inputs (e.g., audio or biometrics) could further improve detection. This work underscores my expertise in computer vision, deep learning, and practical ML deployment—skills I'm eager to apply in future data science endeavors.