Sentiment Analysis of User Comments on LLM Chatbot Applications
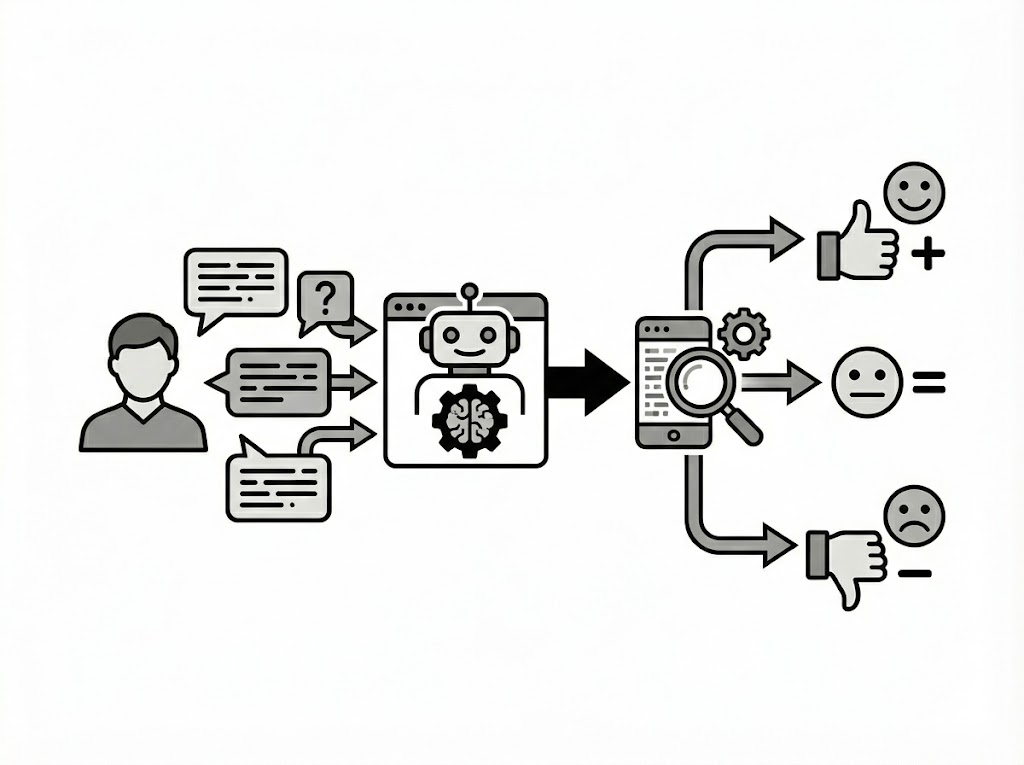
As Large Language Models (LLMs) like GPT, Gemini, Claude, and Grok reshape how we interact with technology, user feedback has become a goldmine for developers. But sifting through thousands of multilingual reviews—riddled with slang, errors, and imbalanced sentiments—is no easy task. That's the challenge my team, "performative males," took on in the Data Analysis Competition (DAC) 2025 Preliminary Round. We built a robust sentiment classification pipeline to turn raw user comments into actionable insights, focusing on positive, negative, and neutral categories. This project not only honed my skills in NLP and machine learning but also demonstrated how to handle real-world data challenges like class imbalance and multilingual text.
The core problem? User reviews for LLM apps are unstructured, often skewed toward positive feedback, and span multiple languages. Manual analysis is impossible at scale, so we needed an automated system that could accurately classify sentiments while prioritizing minority classes (negative and neutral) for better product improvement. Our goal was to create a model optimized for the Macro F1 score, ensuring balanced performance across all classes.
Our Approach: A Multi-Layered Pipeline
We started with thoughtful text preprocessing. Instead of aggressive cleaning that might strip away key signals, we focused on normalization—fixing encoding issues with libraries like ftfy, expanding contractions, and preserving case and punctuation. This kept the data's natural flavor intact for downstream analysis.
Next came feature engineering, where we blended simple stats with cutting-edge semantics:
- Statistical and Lexical Features: We calculated word/character counts, capitalization ratios, punctuation usage, and readability scores to capture tone and complexity. Domain-specific keywords (like "bug," "amazing," or "hallucination") added targeted signals.
- Semantic Features: Leveraging pre-trained transformers like XLM-RoBERTa, mDeBERTa, and DistilBERT, we extracted high-level probabilities as features, capturing context across languages without directly using them for classification.
These features fed into an ensemble of gradient-boosted trees: XGBoost, LightGBM, and CatBoost. We stacked them with a meta-learner and applied post-processing tricks like temperature scaling to calibrate probabilities and bias-only decoding to fine-tune decisions for Macro F1 optimization.
Key Innovations and Challenges
One standout innovation was our handling of class imbalance. Neutral reviews often hid gems like feature requests or bug reports, but they were outnumbered. By using out-of-fold predictions and searching for optimal biases, we shifted boundaries to boost recall on minorities without sacrificing overall accuracy.
We also incorporated metadata like app versions, revealing significant associations with sentiment through chi-square tests—for instance, newer versions showed improved user satisfaction in some apps.
The multilingual aspect was tricky, but transformers' pre-training on diverse corpora made it manageable. Ablation studies confirmed each component's value: dropping transformers slashed performance by nearly 10%.
Results and Impact
Our final ensemble delivered a cross-validation Macro F1 of 0.6651 and a test set score of 0.6693—strong results in a competitive field. This outperformed baselines and highlighted the power of hybrid features and careful calibration. Beyond the numbers, the project provided a framework for AI developers to better understand user pain points, from latency complaints to bias concerns.
Statistic & Data Analysis
Predicting Judicial Sentences: Analyzing Indonesian Court Verdicts with NLP and ML
Statistic & Data Analysis
Evaluating the Impact of Meteorological Data on PM2.5 Prediction Using Tree-Based Machine Learning Models
DS/ML/AI Engineering